软件介绍
RapidMiner Studio是一款专业性极强的数据库类软件。RapidMiner Studio汉化版专门为从事可视化设计工作的用户所打造的,内置丰富的类库素材以及强大的数据挖掘技术,界面简约清爽,功能一目了然,内置1500多种算法与函数库,大大加快了用户的工作效率。
RapidMiner Studio最新版在老版本的基础上对功能进行了全面的升级与优化,用户可以在纯文本文件、Office文档甚至Oracle,MySQL等数据库进行加载,有着极强的实用性与兼容性。而且该软件还会定期对Docker映像进行更新,保证了平台的安全性。
RapidMiner Studio特色
1.数据访问
以任何规模连接到任何数据源,任何格式。
2.数据探索
快速发现模式或数据质量问题
3.数据混合
为预测分析创建最佳数据集。
4.数据清理
专业清理高级算法的数据。
5.造型
快速有效地构建和交付更好的模型。
6.验证
自信而准确地估计模型性能。
RapidMiner Studio功能介绍
1.偏差检测和缓解
接收偏差警告在RapidMiner平台的每个部分,包括Turbo Prep,模型模拟器等。当Studio认为你的专栏可能会导致模型偏差时,你会收到一个警告,以及一个解释它是由什么触发的平台内标注。
2.流媒体和IIOT的进步
在低延迟(50-100ms)的用例中混合和匹配RapidMiner和Python,例如对大量传感器数据评分。此外,当创建设备异常检测模型、基于数据建模物理行为等时,利用新的功能拟合操作符将数据与自定义功能相匹配。
3.安全增强
对Docker无根模式的支持以及Kubernetes环境中增强的安全性都提高了我们的整体安全标准。通过使用最新的安全组件定期更新Docker映像,容器化平台的安全性也得到了提高。
4.时间序列预测
在RapidMiner Go中,基于历史数据自动预测单变量时间序列的未来值。在预测销售或人员需求时,跟踪先进的和季节性的趋势,并使用直观的可视化来比较竞争模型的结果。
5.NLP扩展
利用新的RapidMiner扩展进行自然语言处理,提取语音部分标签,并在自由文本中识别人、城市、组织和其他实体。这通常被用作一种预处理方法,用来确定文档、网站文本等的内容。
RapidMiner安装教程(附破解教程)
1.下载解压,得到RapidMiner Studio软件和crack破解文件夹;
2.首先双击文件“exe”安装软件,依提示安装即可;
3.同意安装协议;
4.选择好安装路径后开始安装;
5.去除运行勾选,点击finish退出安装向导;
6.打开Crack文件夹,将lib文件夹复制替换到安装路径;
【C:Program FilesRapidMinerRapidMiner Studio】
7.运行软件,选择手动激活;
8.输入许可证代码(见压缩包内的readme.txt)
9.至此,软件成功激活,以上就是RapidMiner Studio破解版的详细安装教程(附破解教程)。
rapidminer studio没法启动
这样是加载失败,可能是自己的电脑配置太低,就选选择start normally 进得去,也会发现丢算子等丢包行为。把自己电脑开到最佳性能,再打开就行了
rapidminer studio使用教程
第一次打开RapidMiner Studio时会激活分步教程。阅读介绍并参加导览是一个好主意。
稍后,您可以通过选择File> New Process并选择Learn选项卡来重新打开教程。
该Learn标签链接到以下附加材料:
转到文档
访问社区
观看培训视频
起始页面
学完本教程后,您可以在起始页的帮助下决定下一步:
如果您需要其他指导,或者想要加速数据准备和模型构建,请尝试使用Turbo Prep,RapidMiner的交互式数据准备工具,以及自动模型,RapidMiner的自动化机器学习解决方案。
如果要查看更多示例,请从Samples Repository中的一个模板中进行选择。
如果您想自己动手,请在设计视图中从头开始创建一个新的(空白)流程。
您可以通过选择File> 随时打开“起始页” New Process。
rapidminer studio聚类分析使用教程
分析流程:读取数据库---->聚类分析---->存储csv文件---->结束
1.打开RapidMiner工具,进入白板界面
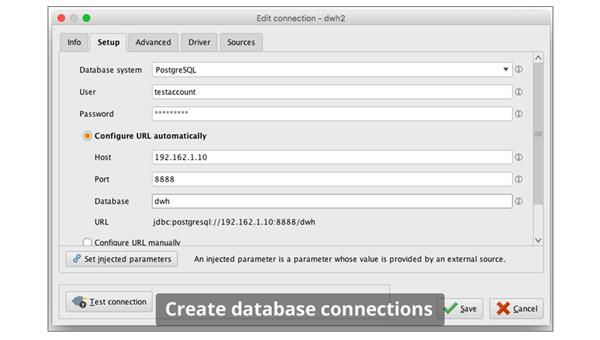
2.读取数据库:拖曳---左侧中的Database--->Read Database标签,读取数据库,然后设置数据库的基本条件,点击白板中的Read Database,查看右侧信息
1)数据库连接条件:点击Connection右边的数据库连接配置按钮,输入相关信息如:数据库名称、用户名、密码、Host等,然后点击下方的测试一下连接是否成功。
2)读取数据库中表以及相关属性数据配置:点击query右侧的图标,选择数据库下的表--属性--以及条件,可以筛选出来对应的数据
3.聚类算法:拖曳---左侧中的Modeling--->segmentation--->K-Means标签到白板中,聚类算法插件,用于数据的聚类分析
1)配置聚类算法的参数:簇数、迭代次数等
4.存储文件:拖曳---左侧中的Data Access--->Files--->Write标签到白板中,存储文件插件,用于分析结果的存储
然后在右侧csv file配置存储路径
5.分析流程图---规划,通过连接线连接整个的执行流程,并点击执行按钮
如图所示
6.执行结果
1)、分析具体结果数据
2)、统计数据:最大、最小、平均值、聚类
3)、聚类分析图
7.结果分析:
1)每科目的最低分、最高分、平均分等信息
2)聚类:三簇数据,每簇数据的学生个数
1)每科分值的分布情况,看出大部分学生的成绩分布在【70-80】之间,90分以上的偏少
1)聚类按三簇进行聚类,也就是说分为了三类学生
2)cluster_0结合第一个图有378个学生实例,从成绩上分析学习情况:地理成绩不及格;语文、化学成绩偏差;物理、英语较好;数学最好
cluster_1结合第一个图有136个学生实例,从成绩上分析学习情况:地理成绩不及格;历史、化学成绩偏差;语文较好;物理、英语、数学最好
cluster_2结合第一个图有26个学生实例,从成绩上分析学习情况:地理成绩不及格;历史、化学成绩偏差;语文、数学、物理较好;英语最好
rapidminer studio视频教程
1.可视化工作流设计器
提高从分析师到专家的整个数据科学团队的生产力
在拖放式可视界面中加速并自动创建预测模型
1500+的丰富库 算法和函数确保了任何用例的最佳模型
针对常见使用情形的预构建模板,包括客户流失、预测性维护、欺诈检测等
《人群的智慧》在每一步都提供积极的建议,帮助初学者
2.连接到任何数据源
处理所有数据,无论数据位于何处
即时创建指向数据库、企业数据仓库、数据湖、云存储、业务应用程序和社交媒体的点击
式连接 随时随地轻松重复使用连接与需要访问的任何人共享它们通过
RapidMiner 市场的扩展连接到新资源
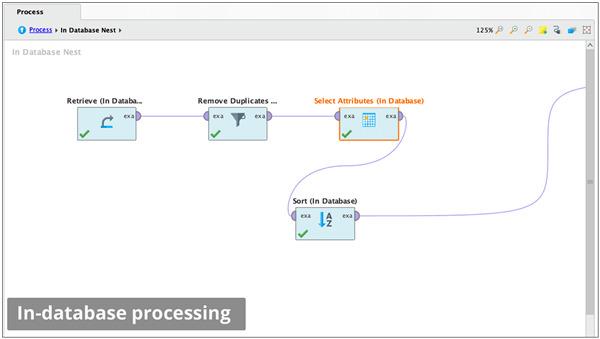
3.自动化的数据库内处理
在数据库内运行数据准备和 ETL,使您的数据针对高级分析进行优化
查询和检索数据,而无需编写复杂的 SQL
利用高度可扩展的数据库集群的强大功能
支持 MySQL、PostgreSQL 和 Google BigQuery
4.数据可视化与探索
评估数据的健康度、完整性和质量
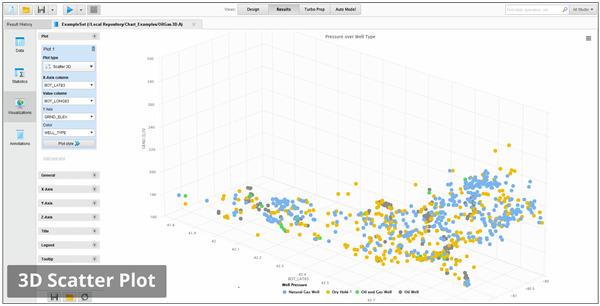
通过散点图、直方图、线图、平行坐标、箱形图等了解模式、趋势和分布
快速找到并修复常见的数据质量问题,包括丢失的值和异常值
使用健壮的统计概述和超过30种交互式可视化探索数据
5.数据准备和混合
消除为预测建模准备数据的麻烦
提供一个完全交互式的点+点击数据准备体验
跨任意数量的数据源提取、联接、筛选和分组数据
创建可计划和共享的可重复的数据准备和ETL流程
6.视觉和自动机器学习
快速创建有影响力的机器学习模型,无需编写代码
RapidMiner Auto Model使用自动机器学习在5次点击中创建模型
从数百种监督和非监督的机器学习算法中选择
实现基本和高级的ML技术,包括回归、集群、时间序列、文本分析和深度学习
构建模型以对诸如成本之类的约束敏感,从而优化预期的业务影响
使用自动化和手动的特征工程来优化模型的准确性

RapidMiner Studio 自动模型
无论您是刚开始使用RapidMiner,还是老手,Auto Model都可以让您的生活更轻松。Auto Model是RapidMiner Studio的扩展,可加速构建和验证模型的过程。最重要的是,它创建了一个您自己可以修改或投入生产的流程 - 没有黑盒子!
Auto Model解决了三大类问题:
预测
聚类
离群值
在预测类别中,您可以解决分类和回归问题。自动模型可帮助您评估数据,提供解决问题的相关模型,并在计算完成后帮助您比较这些模型的结果。
自动模型不仅可以帮助您获得结果; 它还可以帮助您理解这些结果,即使对于内部逻辑可能难以理解的深度学习等模型也是如此。在RapidMiner Studio中,“自动模型”显示为视图,位于“设计”视图,“结果”视图和“Turbo准备”旁边。
示例:预测泰坦尼克号上的生存
为了展示自动模型的工作原理,我们将使用与RapidMiner Studio捆绑的数据集之一,泰坦尼克号数据集,并使用它来预测泰坦尼克号的生存。要开始使用,请Auto Model按RapidMiner Studio顶部的按钮选择视图。
选择数据
启动自动模型后,第一步是从您的某个存储库中选择一个数据集。如果您的数据不在存储库中,请单击屏幕顶部显示“首先导入新数据”的链接。
在我们的示例中,泰坦尼克号数据集可以在Samples> 下找到data。选择此数据集,然后单击Next屏幕底部的。
选择任务
选择数据集后,您必须确定要解决的问题类型。Auto Model识别三个不同的任务:
预测
集群
离群值
在我们的示例中,我们想要预测泰坦尼克号上的生存,因此您应该选择Predict,然后单击“生存”列,然后单击Next。
准备目标
由于“幸存”只有两个值,“是”或“否”,问题是分类问题。通常,对于分类问题,“自动模型”将显示一个条形图,其中包含每个类中的数据点数。当有十个以上的类时,只显示数据点最多的10个类。
最高兴趣等级
在Class of Highest Interest后来变得很重要,当结果呈现,因为性能值,如“精度”和“召回”需要知晓哪些类的应该被解释为“阳性”的结果。在我们关于泰坦尼克号的例子中,Class of Highest Interest是“是”。
将类映射到新值
此步骤包括将目标值从“是”和“否”重命名为其他值的选项。当有两个以上的类时,此选项可能更有用,因为它可用于组合类。输入新值时,请务必Enter按键完成。在我们的示例中,我们将忽略此选项。点击Next继续。
选择输入
并非所有数据列都可以帮助您进行预测。通过丢弃某些数据列,您可以加快模型速度和/或提高其性能。但是你如何做出这个决定呢?关键是你正在寻找模式。如果没有数据的某些变化和一些可辨别的模式,数据可能不会有用。
要注意的事项的快速摘要包括以下内容,其值显示在每个数据列的质量条旁边。
与目标列过于接近或完全不相关的列(相关),
几乎所有值都不同的列(ID-ness),
几乎所有值都相同的列(稳定性),
缺少值的列(缺失)。
自动模型使用颜色编码的状态气泡(红色/黄色/绿色)汇总情况。作为一般规则,最好至少取消选择那些具有红色状态气泡的列,但当然您可以取消选择您喜欢的任何列,而与其状态无关。机器学习模型的输入仅包括所选列。
在泰坦尼克号的情况下,“名称”和“票号”等同于ID。大多数乘客都缺少“客舱”值。因此,在构建模型时,应丢弃带有红色状态气泡的这三列。它们都没有帮助发现模式。
“Life Boat”有一个黄色的状态泡沫,因为此列中的数据与“Survived”高度相关。“救生艇”和“幸存者”实际上是同义词,因此最好从“救生艇”专栏中删除数据,让模型发现生存的根本原因。
换句话说,您希望该模型可以帮助您制定计划。一位乘客无法提前知道他是否会乘坐救生艇,因此不能成为该计划的一部分,但他可以决定支付多少钱,以及是否携带他的家人。
在此示例中,您还应该使用黄色状态气泡“Life Boat”取消选择数据,然后按Next。
型号类型
自动模型为您提供了一系列与您的问题相关的模型。如果没有时间限制,最好的选择可能是构建所有这些,并在完成后比较它们的性能。通常,您必须决定您的优先级:是完成模型的准确性,还是构建它所需的时间?Auto Model可帮助您达成合理的妥协。
在泰坦尼克号示例中,Auto Model提供以下模型:
朴素贝叶斯
广义线性模型
Logistic回归
深度学习
决策树
随机森林
渐变树(XGBoost)
按下Run以构建模型并生成结果。
结果
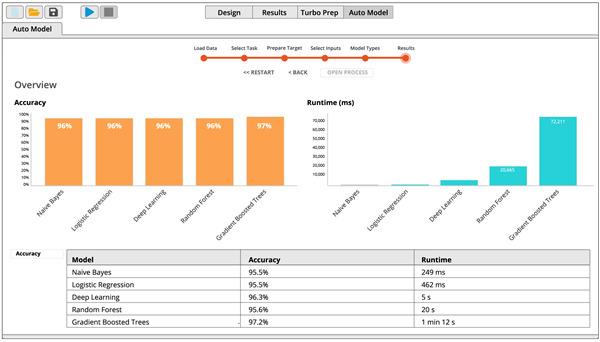
根据您的数据集和您选择的型号,您可能必须等待结果。顶部的进度条跟踪正在进行的计算的状态。您可以通过按下Stop按钮随时停止建模。中间结果在可用时显示,例如,在Comparison> 下Overview。
对于泰坦尼克号数据集,Gradient Boosted Trees(XGBoost)模型需要最长的构建时间,但它也是最准确的模型。请参阅Comparison> Overview比较模型的准确性和运行时间。鉴于Gradient Boosted Trees相对于深度学习的边际性能优势,以及相当长的运行时间,您可能更喜欢在这种情况下使用深度学习模型。
编辑点评:
宣纸君:
本版本延续了前几代所有的优点以及特点,并在此基础上大幅扩展了相关的功能特点,对我来说简直优秀到了极点,真的很不错
特别说明提取码:c053
历史版本
-
RapidMiner Studio Developer 9.10.8 破解版大小:参考文件时间:2023-01-28
下载 -
RapidMiner Studio Developer 9.10.8 破解版(含破解补丁)大小:参考文件时间:2023-01-24
下载 -
RapidMiner Studio破解版 v9.10 中文版大小:273MB时间:2021-09-10
下载